|
Toutf8 converts files from various codepages to UTF-8.
The following codepages are supported:
-
437, 708, 720, 737, 775, 850, 852, 855, 857, 858, 860, 861, 862, 863,
864, 865, 866, 869, 874, 1125, 1250, 1251, 1252, 1253, 1254, 1255, 1256,
1257, 1258, 8859-1, 8859-2, 8859-3, 8859-4, 8859-5, 8859-6, 8859-7,
8859-8, 8859-9, 8859-10, 8859-11, 8859-13, 8859-14, 8859-15, 8859-16,
latin-1, latin-2, latin-3, latin-4, latin-5, latin-6, latin-7, latin-8,
latin-9, latin-10, 037, 273, 277, 280, 285, 297, 500, 1047
The following IANA/MIME charset names are also accepted:
-
ANSI_X3.4-1968, ARMSCII-8, ASCII, CP437, CP850, GEOSTD8, IBM437, IBM850,
ISO_8859-1, ISO-8859-1, ISO-8859-2, ISO-8859-3, ISO-8859-4, ISO-8859-5,
ISO-8859-6, ISO-8859-7, ISO-8859-8, ISO-8859-9, ISO-8859-10, ISO-8859-11,
ISO-8859-13, ISO-8859-14, ISO-8859-15, ISO-8859-16, KOI8-R, KOI8-U,
MACINTOSH, NS_4551-1, TIS-620, US-ASCII, UTF-16BE, UTF-16LE, UTF-7, UTF-8,
UTF8, VISCII, WINDOWS-1250, WINDOWS-1251, WINDOWS-1252,
WINDOWS-1253, WINDOWS-1254, WINDOWS-1255, WINDOWS-1256, WINDOWS-1257, WINDOWS-1258
Example of a toutf8 usage:
s7 toutf8 -437 infile outfile
Operation method
The "charsets.s7i" library contains
definitions of various codepages. Codepages are represented as
constant strings of length 256. Such a codepage string contains the
Unicode representation of all charcters defined by the codepage.
To convert the character 'Σ' from codpage 437 to UTF-32 the following
needs to be done:
-
In codpage 437 the character 'Σ' is encoded with the number 228.
The Unicode representation of 'Σ' is found at cp_437[229].
Note that 229 is used instead of 228 because the index of the first character
in a string is 1 (cp_437[1] defines character 0 of codepage 437).
The expression ord(cp_437[229]) is 931 (or 16#03A3) which is the
Unicode representation of 'Σ'.
All Seed7 source files (*.sd7 and *.s7i) use UTF-8 encoding.
Therefore the Unicode characters used in "charsets.s7i"
are encoded with UTF-8 (an UTF-8 aware editor should be used to
edit files containing UTF-8 characters). Although UTF-8 is
used in the source files the codepage strings define the
conversion to UTF-32 (the internal representation for chars
and strings).
|
|
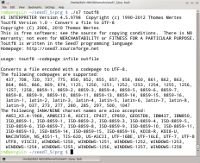
Write usage and allowed conversions |
|
|


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}